
The Machine Learning Workflow Explained (and How You Can Practice It Now)
The 3 components, including the one that most ML curriculums leave out


Most beginners struggle when they break into the AI industry. Why? Everything they learn until then is from the machine learning curriculums designed to teach the theory and some toy projects.
The struggle is predominantly because of the gap between what is expected in the real world against what was taught to them. Sad, yet true.
Don’t get me wrong, those courses are important, and I had done my fair share when I was a beginner. But what is more important is to align with the industry expectations early.
Machine Learning workflows can differ from company to company, so to get the most accurate one, let’s look at few tech giants on how they define them for their own use.
Borrowing the Expertise of These 3 Tech-Giants
Amazon, Google, and Microsoft are three tech giants who have pioneered machine learning in their offerings. All three of them have cloud platforms that help other companies and individual users make the most of machine learning.
At my current work, we use Microsoft Azure as our production environment. Similarly, most companies use either one of these platforms. Their platforms are the closest available resources to real-world production environments.
To understand the typical workflow at these companies, let’s have a look at their own documentations:
- Amazon Web Services discusses its definition of the Machine Learning Workflow: It outlines steps from fetching, cleaning, preparing data, training the models, to finally deploying the model.
- Google Cloud Platform discusses their definition of the Machine Learning Workflow. Google, in addition to the above steps, talks about managing versions of models.
- Microsoft Azure discusses their definition of the Machine Learning Workflow. Microsoft, while resembling the typical workflow of Amazon and Google, emphasizes ML lifecycle management.
We can conclude that the typical workflow is more or less the same for these three companies, and thus we use a combination of their workflows to derive ours.
Let’s dive into these components, shall we?
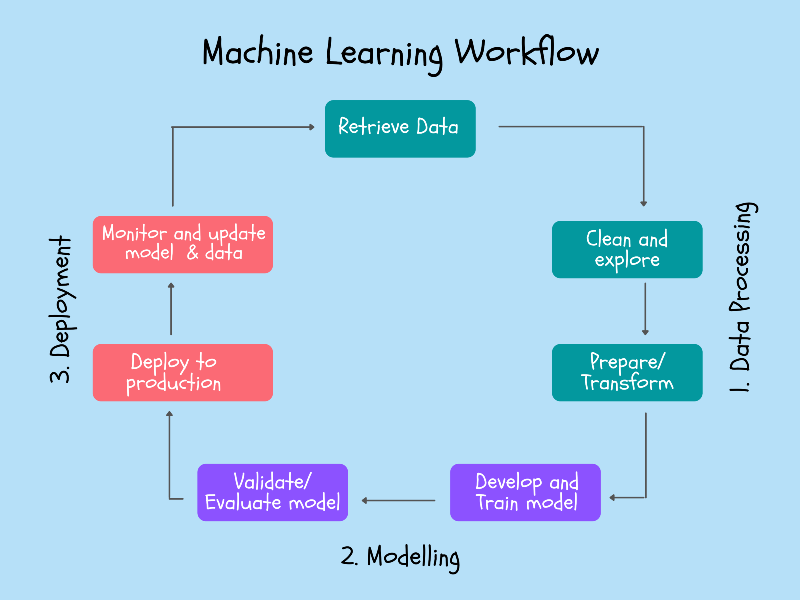
1. Data Processing
You might have heard that 80% of the battle is won if you have the right data.
I can confirm that is true.
In most beginner problems we work on, the data is handed to us on a silver plate (read Kaggle datasets). Hence we never go through the trouble of acquiring them.
Sometimes you get lucky, and the client has been maintaining an efficient database system. Sorry to burst the bubble; I haven’t come across such a client yet.
This component can further be divided into:
- Retrieve data— Data keeps flowing into the businesses; data engineers will design databases and set up an efficient system to store and retrieve the data for modeling purposes.
- Clean and explore data— The raw data needs to be cleaned. Exploring patterns in the data can help data scientists determine features for the models. Anomalous values and outliers will have to be removed from the data.
- Prepare the data — Most ML models expect data in a standard format, so the data must be transformed and then split into the train, validation, and test data sets.
How you can practice this now:
You have already heard these steps from the courses and other blog posts. The gap resides in retrieving data only. It’ll be tempting to skip this step, but you’ll quickly stand out amongst all the aspiring data scientists and machine learning engineers if you work on this.
- Attempt web scraping for data at least once. This web scraping course will give you a headstart. An experience of scraping Twitter, Reddit, Wikipedia, or any possible website can give you the much-needed confidence to acquire data.
- Learn to annotate images. It’s fairly easy to record a video or get them through YouTube. Videos can then be converted into series of images, but everyone should go through the image annotation process at least once. It will be helpful whenever it’s your turn to work on a Computer Vision project.
- Survey to collect data. Next time some friend of yours asks you to fill a survey, notice how the survey was designed. You need to understand how to collect the most important data points with fewer questions, taking care of the respondents' privacy.
Some of these were frustrating and tedious experiences, but hey, how will you even get it done from someone if you’ve never done it yourself in the first place?
These are some steps I took to familiarize myself with the data component, but you’re never limited to these suggestions; I know you get the idea.
2. Modelling
Isn’t this your strength, anyway?
Most find this phase of the workflow the most interesting, and I’m no exception. I love training, tuning, and validating the models. It shouldn’t be surprising that these remain some of the crucial components of the workflow even at Google, Amazon, and Microsoft.
The Modelling component can further be divided into:
- Develop and train model — We use various algorithms and build multiple models on the training data set. Common libraries such as scikit-learn, TensorFlow, and PyTorch have functions built for almost every algorithm, but that shouldn’t stop you from understanding what happens behind the hood.
- Validate and evaluate model — We use the validation dataset to validate and tune the models we built. Similarly, we use the test dataset to evaluate and select the single best model for the problem at hand.
The courses you might have completed do a great job setting you up for the industry, and I don’t even see a gap.
How you can practice this now:
If you’ve done a few courses, I’m sure you’re well aware of these. Honestly, I have nothing to add besides what Andrew Ng teaches in his courses.
No fluff here; let’s move on to the part where most courses leave out.
3. Deployment
I used to think I don’t need to know these concepts as a fresher, but it turned out my boss asked me to work on deployment just weeks into my new job.
The truth is that 95% of the courses ignore this component. Maybe it’s not easy to teach deployment, but we should be putting an extra effort to understand and learn the concepts.
The highly accurate models you’ve built — nobody is going to use it unless you deploy them. That should motivate you to learn and master the final component of the machine learning workflow.
This component can be further detailed into:
- Deploy to production — Deployment is nothing but making the models available for the user through a web or software application.
- Monitor and update data — As time passes, there could be seasonal or sudden changes to the patterns in the data that could make the model performance deteriorate. In such scenarios, the model needs to be updated, going back to the retrieving data phases, thus completing the circle of workflow.
How you can practice this now:
Most beginners, including my past self, struggled to gain exposure in deployment since we can’t replicate the business production environment at home.
The only way out is by going cloud. Most companies use the cloud, and that was my motivation behind this entire workflow.
- Learn to build end user-friendly machine learning apps using a simple library like streamlit. It’ll hardly take you a day.
- Pick any cloud platform as you wish. If you don’t have any preferences, pick Google Cloud Platform. I used them as they offer $300 in free credits in addition to the free tier. Use these to get yourself familiarized with the platform.
- Redo some of your old projects in the cloud. Especially try to make your project available to the end-user through cloud deployment.
- Acquire the cloud-based deployment skills from the courses and documentation available on the platform. If you picked Google Cloud, here’s an excellent specialization of data engineering and machine learning which runs through the entire platform.
Final Thoughts
When I finally broke into data science, I struggled to keep up with the industry's expectations. Even years later, I see most beginners struggling similarly.
The primary reason for this is the gap between what’s taught in the courses and what’s used in the industry. So we looked into the workflows of tech giants such as Google, Amazon, and Microsoft to derive the typical machine learning workflow practiced in the industry.
The components are:
- Retrieve data
- Explore and clean data
- Prepare data
- Develop and train models
- Validate and evaluate models
- Deploy to production
- Monitor and update models
We further dived deep into how we can practice each of these steps. When you went through the workflow, you might have realized your weak spots; my only ask is to start working on them sooner than later.
I hope this article was of use to you. I hope you enjoyed reading this, as much as I enjoyed writing this for you. I appreciate all kinds of feedback on my LinkedIn, so feel free to say Hi or follow me here.
I can’t wait to see you succeed!
As a note of disclosure, this article may have some affiliate links to share the best resources I’ve used at no extra cost to you. Thanks for your support!
For more helpful insights on breaking into data science, honest experiences, and learnings, consider joining my private list of email friends.