
How to Dockerize Any Machine Learning Application
I use these 3 simple steps to do it over and over again.


A month in as a fresh graduate at work, the founder of our AI startup walks to me and asks, “Arunn, I want you to be an expert in Docker. How long would you need?”. Not sure what Docker is, but unable to dodge the question, eventually I replied, “Two weeks, 1 sprint”.
My manager, who was also around, tried interrupting to save me, but I had already done the damage, and all I had was the next two weeks.
Looking back, I was never an expert (nor am I now!), but I learned just enough to do what was required. In this article, I will tell you what’s just enough to dockerize any machine learning web applications.
What is Docker?
Docker is a tool designed to create, deploy, and run applications by using containers. A Container is a standardized software unit, in simple terms — nothing but a packaged bundle of application code and required libraries and other dependencies. A Docker Image is an executable software package that includes everything needed to run an application and becomes a Container at runtime.
It was a lot of new technical terms when I tried to understand Docker. But the idea is actually simple.
Think of it like you get a fresh mini Ubuntu machine. Then you install some packages on top of it. Then you add some code on top of it. And finally, you execute the codes to create an application. All of this happens on top of your existing machine with the operating system of your choice. All you need is to have Docker installed in it.
If you do not have Docker installed on your machine, please find instructions here to set up Docker.
Why Docker for Data Scientists?
I get it. You’re in the field of data science. You think the DevOps guys can take care of Docker. Your boss didn’t ask you to become an expert (unlike mine!).
You feel you don’t really need to understand Docker.
That’s not true, and let me tell you why.
“Not sure why it’s not working on your machine, it’s working on mine. Do you want me to have a look?”
Ever heard these words uttered at your workplace? Once you (and your team) understand Docker, nobody will ever have to utter those words again. Your code will run smoothly in Ubuntu, Windows, AWS, Azure, Google Cloud, or anywhere, as a matter of fact.
The applications you build become reproducible anywhere.
You’ll start spinning up environments much faster and distribute your applications the right way, and you’ll be saving a lot of time. You’ll (eventually) be known as a Data Scientist with software engineering best practices.
The 3 Simple Steps
As promised, I have simplified the process into 3 simple steps. Here let’s use a use-case of a diabetes prediction app, which can predict the onset of diabetes based on the diagnostic measure. This would give you an understanding of how we can approach containerization in a real-world use case scenario.
I highly recommend you go through this article in which we build this Machine Learning App from scratch in a step by step process using Streamlit.
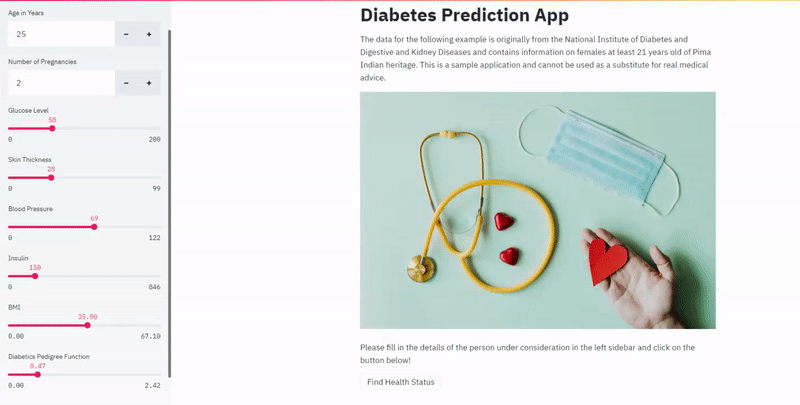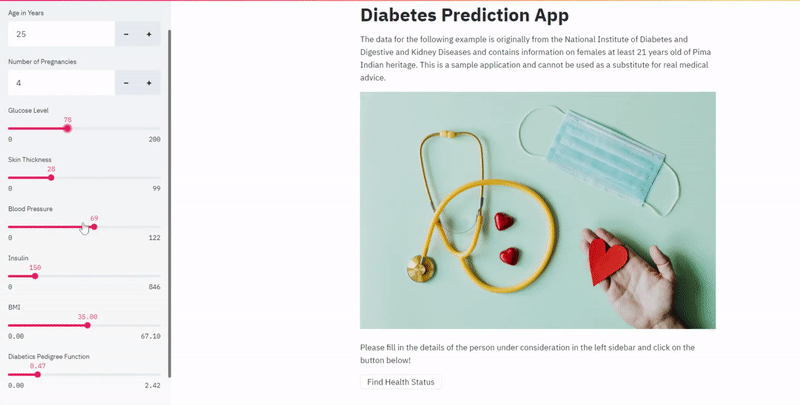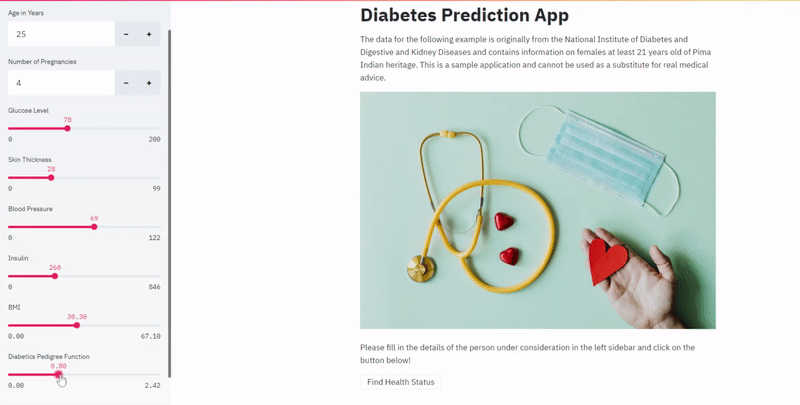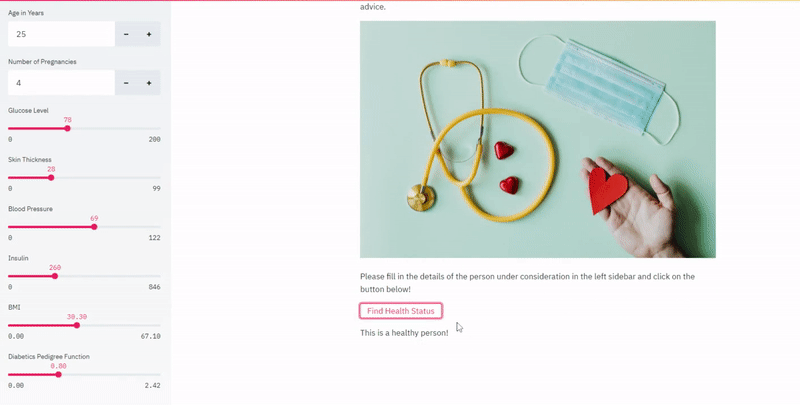
Please have a look at this GitHub repository with the complete implementation to follow along with the example. Now that we know the context let’s tackle down our 3 steps!
1. Defining the environment
The first step is to ensure the exact required environment for the application to function properly. There are many ways to do this, but one of the simplest ideas is to define requirements.txt file for the project.
Please have a look at all the libraries used in your code and list them down in a text file named requirements.txt. It’s a good practice to list the exact version of the library, which you can find out when you run pip freeze on the terminal of your environment. My requirements file for the diabetes prediction example looks like this,joblib==0.16.0
numpy==1.19.1
pandas==1.1.0
pandas-profiling==2.8.0
scikit-learn==0.23.2
streamlit==0.64.0
2. Writing the Dockerfile
The idea here is we are trying to create a file named Dockerfile that can be used to build the required virtual environment for our app to run on. Think of it as our instructions manual on building the required environment on top of any system!
Let’s write our Dockerfile for the example in hand,
FROM python:3.7EXPOSE 8501WORKDIR /appCOPY . .RUN pip install -r requirements.txtCMD streamlit run app.pyThat’s it. 6 lines of code. All in sequence. Every line builds on top of the previous one. Let’s dissect the lines.
- Every Dockerfile has to start with a FROM command. What follows FROM must be an already existing image (either locally on your machine or from the DockerHub repository). Since our environment is based on python, we use
python:3.7as our base image and eventually create a new image using this Dockerfile. - Streamlit runs on a default port of 8501. So for the app to run, it is important to expose that particular port. We use the EXPOSE command for that.
- WORKDIR sets the working directory for the application. The rest of the commands will be executed from this path.
- Here COPY command copies all of the files from your Docker client’s current directory to the working directory of the image.
- RUN command ensures that the libraries we defined in the
requirements.txtare installed appropriately. - CMD specifies what command to run within the container as it starts. Hence
streamlit run app.pyensures that the Streamlit app would run as soon as the container has spun up.
Writing Dockerfiles takes some practice, and you can’t possibly master all of the commands available unless you spend a lot of time with Docker. I recommend getting comfortable with some basic commands and referring to the docker's official documentation for everything else.
3. Building the image
Now that we have defined the Dockerfile, it’s time to build it and create an image. The idea is this image we create is the reproducible environment irrelevant to the underlying system.
docker build --tag app:1.0 .As the name suggests build command builds the image layer by layer as defined in the Dockerfile. It’s always a good practice to tag an image with a name and version number as <name>:version.number . The dot in the end signifies the path for the Dockerfile, which is the current directory.
Wait, I built the image, but what do I do with it? Depending on the requirements, you can share the built images on DockerHub or deploy them on the cloud and so on. But first, now you run the image to get the container.
As the name suggests, the run command runs the specified container on the host machine. --publish 8501:8501 lets the port 8501 of the container to be mapped to the port 8501 of the host machine, while -it is needed for running interactive processes (like shell/terminal).docker run --publish 8501:8501 -it app:1.0
Now follow the link prompted on your terminal to see the magic yourself! ;)

Before you go
This article is a part of my series on Machine Learning in Production:
- How I Build Machine Learning Apps in Hours
- How to Dockerize Any Machine Learning Application
- Deploying Your Machine Learning Apps
Thank you for reading this far. I hope this article added some value to you and helped you get started with Docker for data science. Despite using it for years now, I don’t consider myself an expert. But I feel confident knowing just enough and wanted to share the little I know with all of you. I can’t wait to see you all start acing Docker. I write extensively about my experiences in data science and would extremely appreciate your feedback.
Want to keep in touch? Join my private list of email friends.